 Fraunhofer Institute for Integrated Circuits IIS
Fraunhofer Institute for Integrated Circuits IISArtificial intelligence is mostly implemented with deep learning, i.e., with specially trained deep and thus complex artificial neural networks. Once trained, networks can be significantly reduced in complexity without significant loss of quality, allowing for more efficient transmission and execution. Techniques for this area referred to as Deep Compression. Deep Compression can be used to shrink a typical network by a factor of 10, for example, before it is distributed to users via a cellular network. The savings in time and energy are immediate.

Deep Compression
Knowledge Nugget Deep Compression

Privacy warning
With the click on the play button an external video from www.youtube.com is loaded and started. Your data is possible transferred and stored to third party. Do not start the video if you disagree. Find more about the youtube privacy statement under the following link: https://policies.google.com/privacy
Technologie
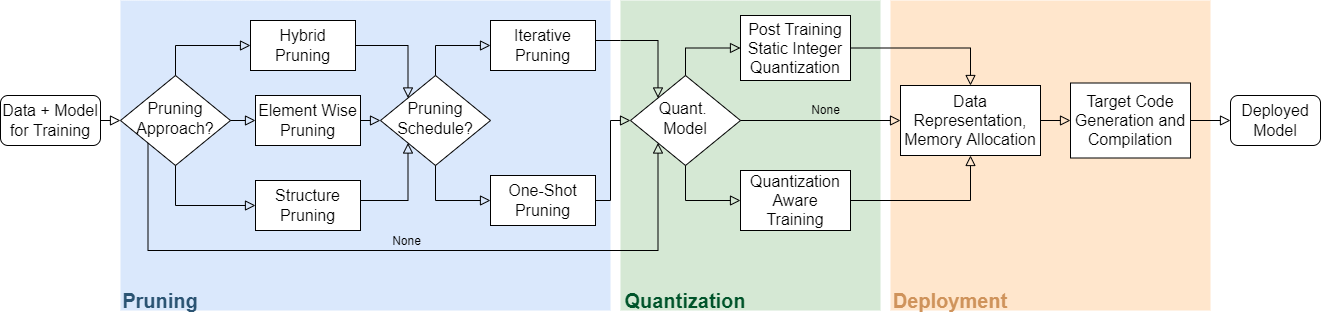
Deep artificial neural networks, or deep learning, are now an indispensable part of artificial intelligence (AI) applications. Particularly in the initial problem solution, very large and complex models are often generated here. These then require a lot of computing power, memory, energy and, last but not least, transmission capacity during application. Reducing model capacity reduces this footprint and therefore not only costs, but is also a path to greener and more sustainable AI.
The research branch of deep compression deals with the automatic reduction of model capacity of a trained neural network while maintaining the necessary performance. Established methods are pruning, the targeted trimming of the network by removing connections, filters and neurons. Furthermore, this also includes the quantization of the weights of floating point numbers to a few bits. Furthermore, even more advanced methods have been developed such as the reduction of weight and filter tensors by projection into lower dimensional subspaces. Also systematic structural conversions like the replacement of high dimensional by several one dimensional convolutions or the separation of convolution operations belong to it. Lossless compression techniques such as DeepCABAC are also used for the transfer.
Demonstration
The figure on the right shows how, for example, noise detection can be performed on an embedded system in a very energy-saving way using deep compression.
The same is true for applications in computer vision, motion classification for wearables, or anomaly detection in condition monitoring.
The uncompressed AI model on the left can only be run on larger platforms with conventional CPU (classification accuracy 97%, 22 watts),
whereas the compressed network can be run on a microcontroller (classification accuracy 97 %, 0.1 Watt).

Scientific publications
Recipes for Post-training Quantization of Deep Neural Networks
Ashutosh Mishra, Christoffer Löffler, Axel Plinge
In: Workshop on Energy Efficient Machine Learning and Cognitive Computing; Saturday, December 05, 2020 Virtual (from San Jose, California, USA)
Given the presence of deep neural networks (DNNs) in all kinds of applications, the question of optimized deployment is becoming increasingly important. One important step is the automated size reduction of the model footprint. Of all the methods emerging, post-training quantization is one of the simplest to apply. Without needing long processing or access to the training set, a straightforward reduction of the memory footprint by an order of magnitude can be achieved. A difficult question is which quantization methodology to use and how to optimize different parts of the model with respect to different bit width. We present an in-depth analysis on different types of networks for audio, computer vision, medical and hand-held manufacturing tools use cases; Each is compressed with fixed and adaptive quantization and fixed and variable bit width for the individual tensors.
Getting AI in your pocket with deep compression
Ashutosh Mishra, Axel Plinge
Deep neural networks (DNNs) have become state-of-the-art for a wide range of applications including computer vision, speech recognition, and robotics. The superior performance often comes at the cost of high computational complexity. The process of creating and training a DNN model is difficult and labor-intense, and the resulting models rarely optimized for running on embedded devices. Automated techniques to improve energy efficiency and speed without sacrificing application accuracy are vital. Big companies showed that compressing weights or squeezing the architecture can reduce the model complexity by a factor of 20-50 while maintaining almost identical performance. The field of 'deep compression' has become a dedicated branch of research. Technical support for such optimizations is starting to be available by a growing set of tools. This talk gives an overview of deep compression techniques and tools with example applications.
Publications
2025
Deutel, M., Kontes, G., Mutschler, C., & Teich, J. (2025):
In: Genetic and Evolutionary Computation Conference (GECCO)
Deutel, M., Kontes, G., Mutschler, C., & Teich, J. (2025).
In: ACM Transactions on Evolutionary Learning and Optimization
2024
Witt, N., Deutel, M., Schubert, J., Sobel, C., & Woller, P. (2024)
Energy-Efficient AI on the Edge
In: Unlocking Artificial Intelligence: From Theory to Applications (pp. 359-380)
Deutel, M., Hannig, F., Mutschler, C., & Teich, J. (2024):
On-Device Training of Fully Quantized Deep Neural Networks on Cortex-M Microcontrollers
In: IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 2024
Deutel, M., Hannig, F., Mutschler, C., & Teich, J (2024):
Fused-Layer CNNs for Memory-Efficient Inference on Microcontrollers
In: Workshop on Machine Learning and Compression, NeurIPS 2024
2023
Deutel, M., Woller, P., Mutschler, C., & Teich, J. (2023, March).
In: MBMV 2023; 26th Workshop (pp. 1-12). VDE
Deutel, M., Mutschler, C., & Teich, J. (2023).
microYOLO: Towards Single-Shot Object Detection on Microcontrollers
In: ECML PKDD Conference, Workshop on IoT, Edge, and Mobile for Embedded Machine Learning, 2023