 Fraunhofer-Institut für Integrierte Schaltungen IIS
Fraunhofer-Institut für Integrierte Schaltungen IISKünstliche Intelligenz wird meist mit Deep Learning umgesetzt, also mit speziell trainierten tiefen und damit komplexen künstlichen neuronalen Netzen. Einmal trainierte Netze können ohne wesentliche Qualitätseinbußen in ihrer Komplexität deutlich reduziert werden, was eine effizientere Übertragung und Ausführung ermöglicht. Techniken hierfür werden mit Deep Compression bezeichnet. Mit Deep Compression lässt sich etwa ein typisches Netzwerk um den Faktor 10 schrumpfen, bevor es über ein Mobilfunknetz an die Anwender verteilt wird. Die Einsparung an Zeit und Energie ist unmittelbar.

Deep Compression
Wissensnugget Deep Compression

Datenschutz und Datenverarbeitung
Wir setzen zum Einbinden von Videos den Anbieter YouTube ein. Wie die meisten Websites verwendet YouTube Cookies, um Informationen über die Besucher ihrer Internetseite zu sammeln. Wenn Sie das Video starten, könnte dies Datenverarbeitungsvorgänge auslösen. Darauf haben wir keinen Einfluss. Weitere Informationen über Datenschutz bei YouTube finden Sie in deren Datenschutzerklärung unter: https://policies.google.com/privacy
Technologie
Tiefe künstliche neuronale Netze, das Deep Learning, ist heute aus der Anwendung künstlicher Intelligenz (KI) nicht mehr wegzudenken. Gerade bei der initialen Problemlösung werden hier oft sehr große und komplexe Modelle erzeugt. Diese benötigen dann bei der Anwendung viel Rechenleistung, Speicher, Energie und nicht zuletzt Übertragungskapazität. Eine Reduktion der Modellkapazität verringert diesen Fußabdruck und daher nicht nur Kosten, sondern ist auch ein Weg zu einer grüneren und nachhaltigeren KI.
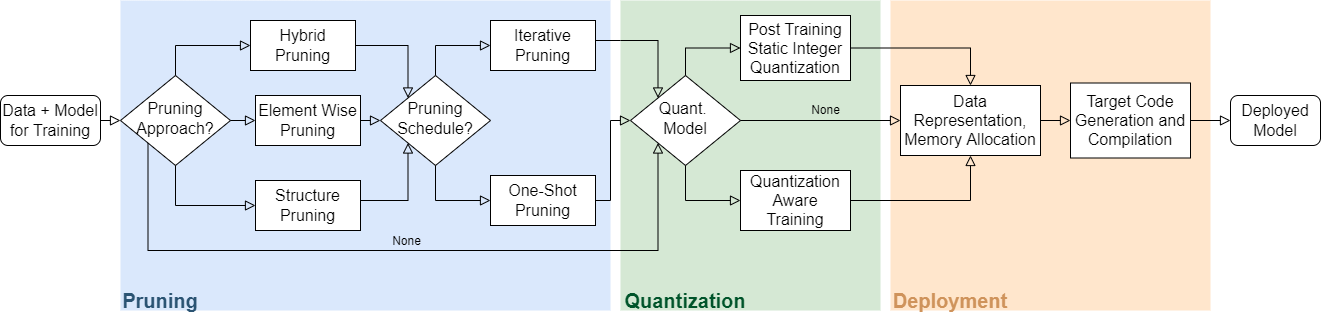
Der Forschungszweig der Deep Compression beschäftigt sich mit der automatische Reduktion von Modellkapazität eines trainierten neuronalen Netzes bei gleichzeitigem Erhalt der nötigen Performance. Etablierte Verfahren sind zum einen das Pruning, das gezielte beschneiden des Netzwerkes durch Entfernen von Verbindungen, Filtern und oder Neuronen. Des Weiteren gehört hierzu auch die Quantisierung der Gewichte von Fliesskommazahlen auf wenige Bits. Darüber hinaus sind noch weitergehende Verfahren entwickelt worden wie die Reduktion von Gewichts- und Filtertensoren durch Projektion in niedriger dimensionale Unterräume. Auch systematische strukturelle Umbauten wie die Ersetzung von hochdimensionaler durch mehrere eindimensionale Faltungen oder die Separation von Faltungsoperationen zählen dazu. Für die Übertagung kommen auch verlustfreie Kompressionsverfahren wie etwa DeepCABAC zum Einsatz.
Demonstration
Die Abbildung rechts zeigt, wie sich beispielsweise eine Geräuscherkennung durch Deep Compression sehr energiesparende auf einem eingebetteten System ausführen lässt.
Ähnliches gilt auch für Anwendungen aus dem Bereich Computer Vision, Bewegungsklassifikation für Wearables oder zu Anomaliedetektion im Condition Monitoring.
Das unkomprimiertes KI Modell auf der linken Seite kann nur auf größeren Plattformen mit herkömmlicher CPU ausgeführt werden (Klassifikationsgenauigkeit 97 %, 22 Watt),
wohingegen das komprimierte Netz auf einem Mikrokontroller ausgeführt werden kann (Klassifikationsgenauigkeit 97 %, 0,1 Watt).

Publikationen
2025
Deutel, M., Kontes, G., Mutschler, C., & Teich, J. (2025):
In: Genetic and Evolutionary Computation Conference (GECCO)
Deutel, M., Kontes, G., Mutschler, C., & Teich, J. (2025).
In: ACM Transactions on Evolutionary Learning and Optimization
2024
Witt, N., Deutel, M., Schubert, J., Sobel, C., & Woller, P. (2024)
Energy-Efficient AI on the Edge
In: Unlocking Artificial Intelligence: From Theory to Applications (pp. 359-380)
Deutel, M., Hannig, F., Mutschler, C., & Teich, J. (2024):
On-Device Training of Fully Quantized Deep Neural Networks on Cortex-M Microcontrollers
In: IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 2024
Deutel, M., Hannig, F., Mutschler, C., & Teich, J (2024):
Fused-Layer CNNs for Memory-Efficient Inference on Microcontrollers
In: Workshop on Machine Learning and Compression, NeurIPS 2024
2023
Deutel, M., Woller, P., Mutschler, C., & Teich, J. (2023, March).
In: MBMV 2023; 26th Workshop (pp. 1-12). VDE
Deutel, M., Mutschler, C., & Teich, J. (2023).
microYOLO: Towards Single-Shot Object Detection on Microcontrollers
In: ECML PKDD Conference, Workshop on IoT, Edge, and Mobile for Embedded Machine Learning, 2023
2020
Mishra, A., Löffler, C., & Plinge, A.
Recipes for Post-training Quantization of Deep Neural Networks
In: Workshop on Energy Efficient Machine Learning and Cognitive Computing; Saturday, December 05, 2020 Virtual
Mishra, A., Plinge, A.
Getting AI in your pocket with deep compression
In: Embedded World 2020